SDR runtimes¶
This contains benchmarks of the following SDR runtimes:
All the tests are run in a Kria KV260, which has a quad-core Cortex-A53 running at 1.333 GHz.
The same kind of flowgraph is used in all the SDR runtimes. There are three types of blocks in the flowgraph:
Dummy Source. This block pretends to produce output by immediately telling the runtime that it has produced as many items as are available on the output buffer, but without actually writing to the output buffer. This block is intended to be almost zero-cost.
Saxpy. This block runs the Saxpy kernel that was benchmarked in the Saxpy Rust implementation section. The kernel is a highly optimized implementation in aarch64 assembly of the
y[n] = a * x[n] + bmathematical operation using 32-bit floats. An out-of-place version of the kernel that uses separate input and output buffers is used. The throughput of this kernel is the same as the in-place kernel benchmarked in that section, almost 1 float per clock cycle when the buffer size is long enough.Benchmark Sink. This block acts as a null sink, by consuming all the available input without reading from the input buffer. When enough samples have been consumed, the block measures the elapsed time to determine the sample rate at which the flowgraph is running. This block is intended to be almost zero-cost.
A Dummy Source is connected to a chain of Saxpy blocks, and the output of this chain is connected to a Benchmark Sink.
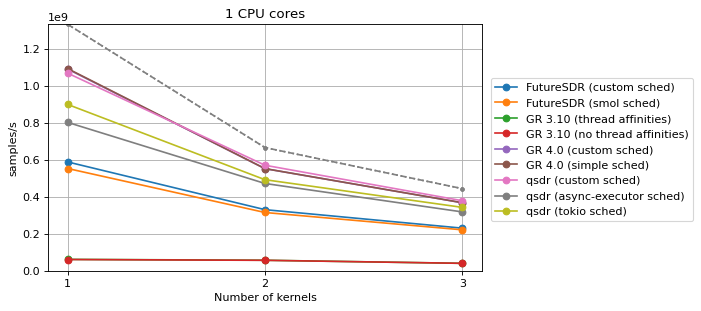
Single-core and single-kernel¶
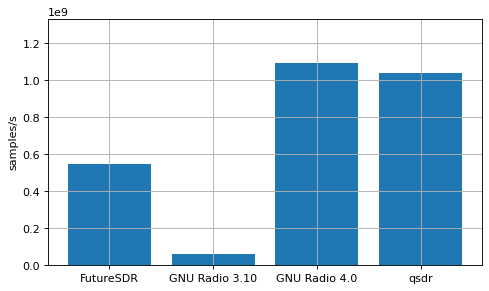
In this benchmark, a single Saxpy block is present in the flowgraph. All the three blocks are run in the same CPU core. The performance should be very close to the theoretical maximum of 1.333 Gsps (depicted as the maximum value of the y axis). Any performance decrease is attributed to the SDR runtime.
In FutureSDR, the smol scheduler with one executor and CPU pinning is used. In GNU Radio 3.10, thread affinity is used to pin the three blocks to the same CPU. In GNU Radio 4.0, the simple single-threaded scheduler is used. In qsdr, a custom scheduler that runs all the blocks sequentially in one thread is used.
The performance of GNU Radio 3.10 is very poor compared to the other SDR runtimes. This is attributed to very high overhead when calling each block. In fact, the Dummy Source and Benchmark Sink are very far from being almost zero-cost, and the CPU usage of their threads is comparable to that of the Saxpy block thread.
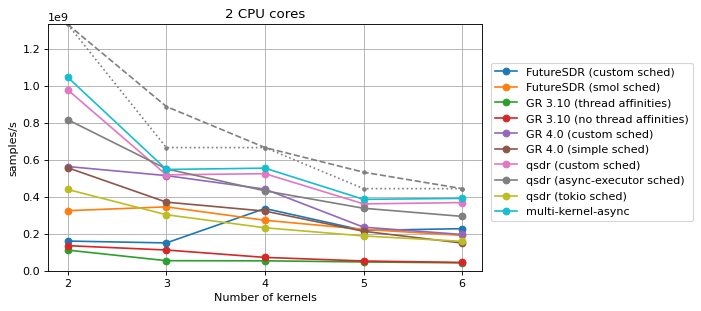
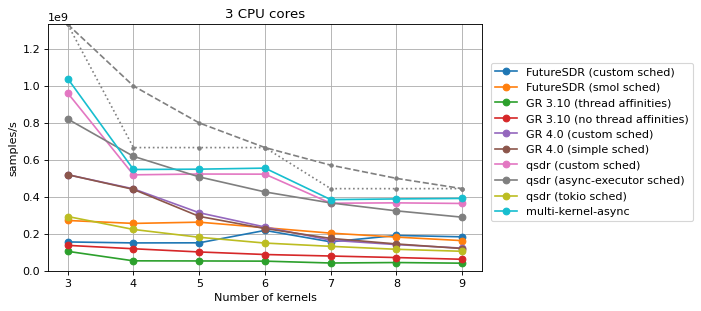
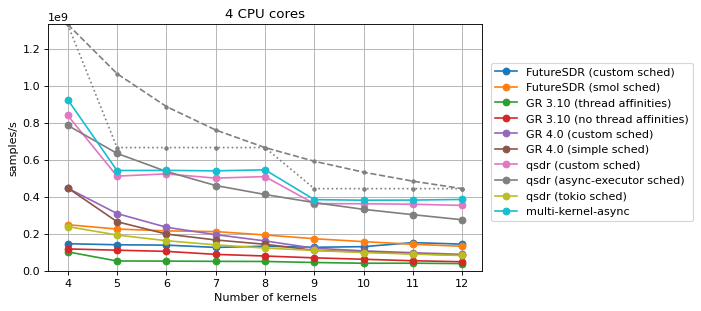
Multi-core and multi-kernel¶
This benchmark depends on two parameters, the number N of CPU cores to be
used, which goes from 1 to 4, and the number M of Saxpy blocks present in
the flowgraph, which goes from N to 3*N.
Two scheduling strategies are benchmarked for each SDR runtime other than qsdr:
The default scheduling strategy. For FutureSDR this is the smol scheduler with
Nexecutors and CPU pinning. In GNU Radio 3.10, CPU affinities are used to limit the set of CPUs in which the blocks can run to the firstNCPUs, but otherwise the Linux kernel is free to schedule these blocks over the set of allowed CPUs. In GNU Radio 4.0, the simple multi-threaded scheduler with a custom thread pool ofNworker threads is used. The worker threads have no CPU affinity, so the Linux kernel is free to scheduler them over all the CPU cores.A custom scheduling strategy designed with this flowgraph in mind. If
Mis divisible byN, this strategy allocates the Dummy Source and the firstM/NSaxpy blocks in the chain to the first CPU core, the nextM/NSaxpy blocks in the chain to the next CPU core, and so on until reaching theN-th CPU core, to which the lastM/NSaxpy blocks as well as the Benchmark Sink are allocated. IfMis not divisible byN, then firstM % NCPU cores get allocatedfloor(M/N) + 1Saxpy blocks, and the remaining CPU cores get allocatedfloor(M/N)Saxpy blocks. In FutureSDR achieved by using a custom CPU pin scheduler that uses a flow scheduler with a local queue for each worker thread that contains the blocks allocated to that thread, in flowgraph order. In GNU Radio 3.10 this is achieved by using CPU affinities to pin each block to its correspoinding CPU. In GNU Radio 4.0 this is achieved by a custom multi-threaded scheduler that forms job lists containing the blocks allocated each thread, in flowgraph order.
For qsdr, there is no default scheduling strategy. A custom strategy as defined
above is used. Additionally, the performance of qsdr with the work-stealing
runtimes from the async-executor and Tokio crates, with N worker threads each pinned to a
different CPU core is also benchmarked.
In each plot, dashed or dotted grey lines are depicted that show the theoretical maximum performance of two types of ideal schedulers:
A scheduler that distributes dynamically and fairly all the Saxpy blocks over all the available CPUs. The performance of that scheduler is
N/Mtimes that of the performance of a single Saxpy block.A scheduler that statically distributes the Saxpy blocks over the available CPUs. The performance of that scheduler is
1/ceil(M/N)times that of the performance of a single Saxpy block. It only matches the previous scheduler whenNdividesM. In other cases it performs worse.
Additionally, for more than one CPU core, the performance of the multi-kernel
async benchmark from the Saxpy Rust implementation section is shown. The
parameters for this kernel are N+1 buffers, where N is the number of
CPUs, and a buffer size of 16 kiB. This multi-kernel-async benchmark gives an
indication of what could be achieved by an SDR runtime that had minimal
overhead, in the case where the Saxpy blocks are statically distributed over the
available CPUs.