Saxpy Rust implementation¶
This shows the results of several benchmarks of a “Saxpy” kernel, which computes
y[n] = a * x[n] + b using 32-bit floats. The Saxpy kernel works in-place on
a buffer. It is a highly optimized implementation in aarch64 assembly that has a
throughput of almost one float per clock cycle on a Cortex-A53 when the buffer
is long enough, assuming all the memory accesses hit the L1 cache (for short
buffers the overhead of starting the kernel pipeline needs to be taken into
account).
The benchmarks are run on a Kria KV260, which has a quad-core Cortex-A53 running at 1.333 GHz with 32 kiB of L1 data cache for each core and 1 MiB of L2 cached shared between the four cores.
The benchmarks are implemented by benchmark_saxpy in the qsdr-benchmarks
crate.
Single-core benchmarks¶
The following benchmarks run on a single thread pinned to one CPU core. The theoretical maximum performance of these benchmarks is 1.333 Gsps, because the Saxpy kernel has a theoretical maximum of one float per clock cycle. This theoretical maximum performance is shown as the maximum value of the y scale in all the plots.
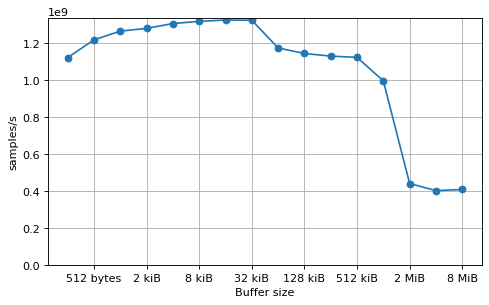
Buffer size benchmark¶
This benchmark shows the throughput of a single Saxpy kernel run repeatedly on the same buffer, depending on the buffer size. The overhead for a small buffer size can be seen for buffer sizes below 8 kiB (2048 floats). A performance drop can be seen for buffer sizes over 16 kiB, due to the data no longer fitting in the L1 cache (the L1 cache size is 32 kiB). A much larger performance drop appears for data sizes over 512 kiB, due to the data no longer fitting in the L2 cache (the L2 cache size is 1 MiB).
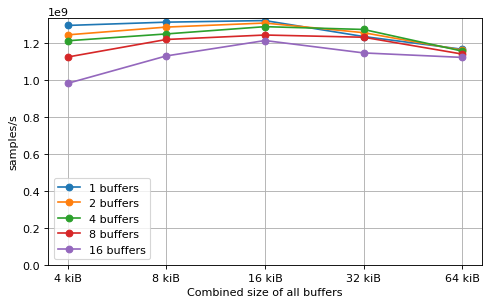
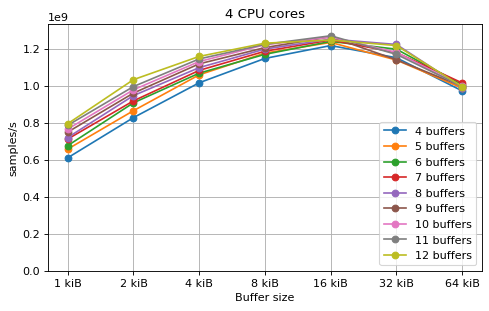
Buffer number benchmark¶
This benchmark studies the effects of executing the Saxpy kernel by looping over
different buffers. A set of N buffers is created at the beginning of the
benchmark, and the kernel is executed in a loop for each of these buffers. The x
axis of the plot indicates the sum of the sizes of all the buffers, since the
main factor that determines the performance is whether all the buffers can fit
in the caches at the same time. The optimal performance is achieved only when
all the buffers fit into L1. There is a slight performance drop caused by using
a larger number of buffers, but this is mostly due to the smaller size of each
buffer to achieve the same combined size.
Multi-core benchmarks¶
These benchmarks study the performance of running a Saxpy kernel simultaneously in several cores. In each benchmark, a certain number of threads between 2 and 4 is created. The threads are connected in a loop using channels. A certain number of buffers is created, and the buffers are all injected into the receive channel of the first thread. Each thread is pinned to a different CPU core. The threads receive a buffer from their input channel, run the Saxpy kernel on the buffer, and send the buffer to their output channel.
There are four categories of benchmarks depending on two factors:
Whether the channels are sync or async. The sync case uses the optimized channels from
qsdr::channel::futex. The async case uses the optimized channels fromqsdr::channel::futures. In the async case, each thread runs theblock_onexecutor fromqsdr-benchmarks.Whether “fake message passing” mode is used. In order to distinguish the effects of the overhead due to message passing over the channels from the overhead due to data movement between the L1 caches of different CPUs, the “fake message passing” mode is introduced. In this mode, buffers are passed between the threads as normal, but each thread also has a single private buffer. The Saxpy kernel is always executed on the private buffer instead of on the buffer that has just been received over the channel. This eliminates the data movement between L1 caches, because each thread reads and writes from their own buffer, but maintains all the overhead related to message passing.
Another parameter that is varied in each benchmark is the number of buffers that
exist in the system. If there are N cores, at least N buffers are needed
for all of the cores to be able to work simultaneously. Sometimes a larger
number of buffers can provide an advantage by preventing the cores from starving
occassionally, but using more buffers has the disadvantage of using more memory
and potentially spilling out of the caches.
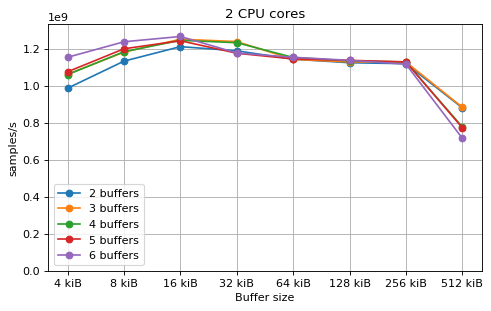
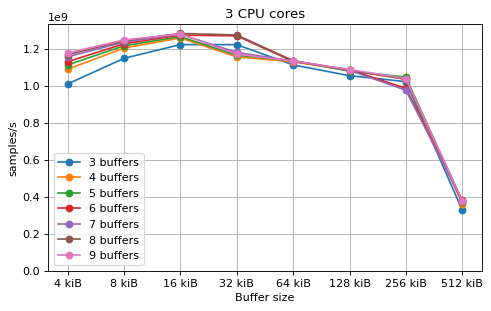
Multi-core¶
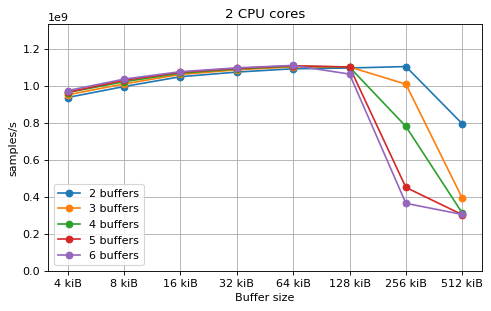
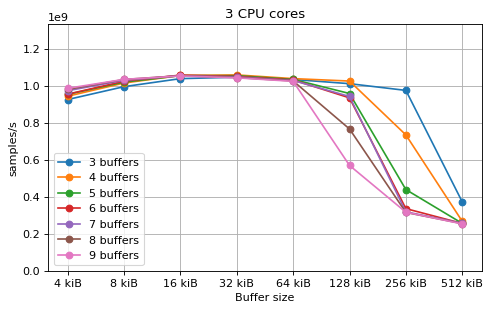
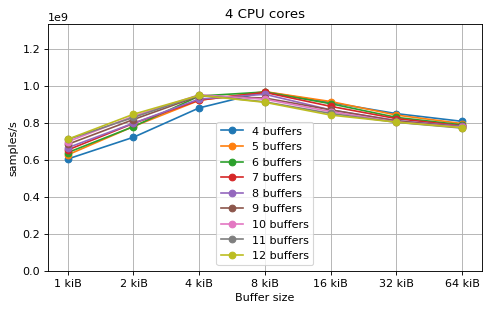
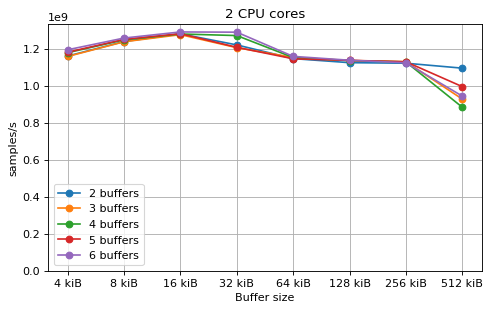
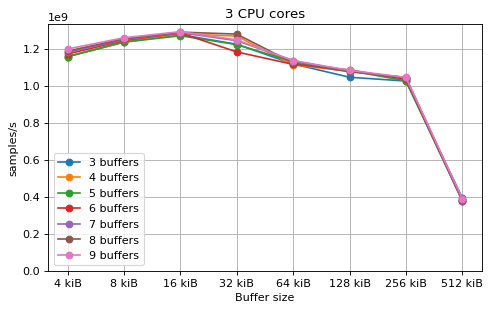
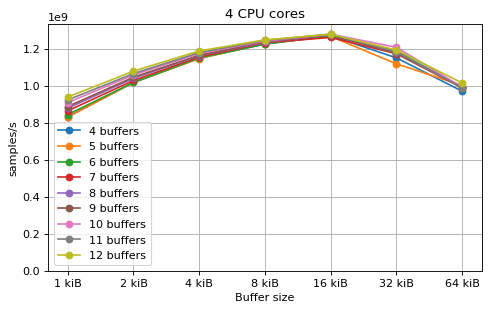
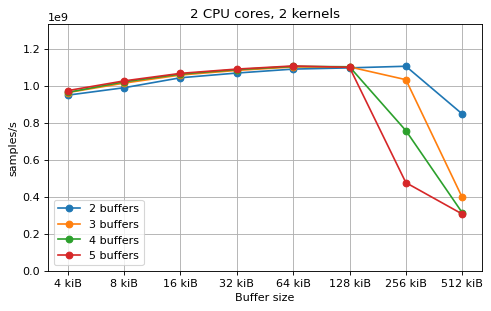
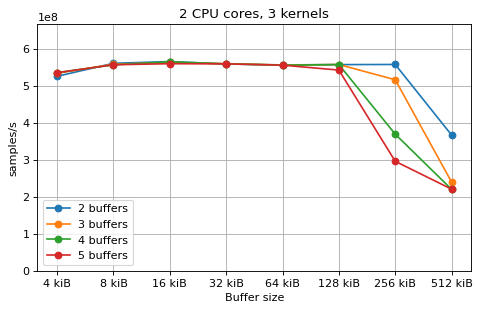
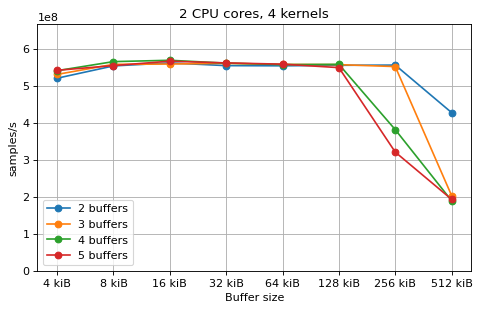
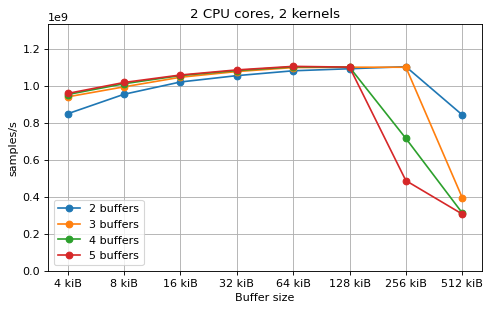
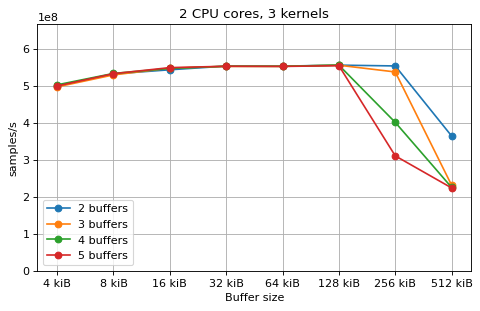
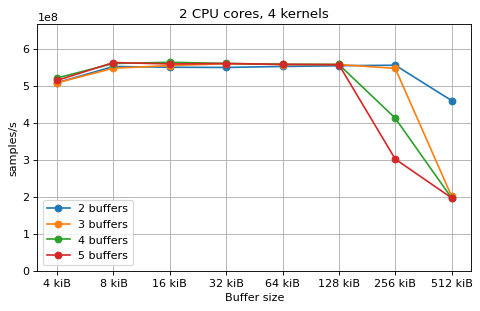
This is a benchmark with sync channels and without fake message passing. With 2 CPU cores, the performance appears to be limited by data movement between the L1 caches. Larger buffers that do not fit into L1 are favourable, as long as all the buffers still fit into L2. In this case the performance is similar to a single thread running from a buffer that spills into L2. With 3 CPU cores the performance is slightly worse, and somewhat smaller buffers are favourable. The case of 4 CPU cores favours even smaller buffers, and also comes with a small decrease in performance.
For 2 and 3 CPUs cores, all the tested number of buffers provide very similar performance, as long as all the buffers fit into the L2 cache. For 4 CPU cores the situation is slighly different: for small buffer sizes a larger number of buffers performs better, while for a larger buffer size, 5 buffers is optimal.
Multi-core with fake message passing¶
This is a benchmark with sync channels and fake message passing, so the effects of data movement between the L1 caches are eliminated. The performance is only slightly worse than the single-core performance. This means that the overhead due to message passing using the channels is small, and that most of the overhead when using a multi-core system comes from the data movement between the L1 caches.
Multi-core async¶
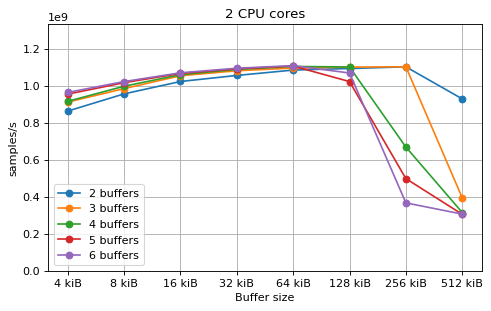
This is a benchmark with async channels and without fake message passing. The results are very similar to the corresponding sync channels benchmark. This shows that the overhead of async channels is very small, despite them being much slower than the sync channels in the Rust channels benchmark.
A difference between async and sync channels is that using only N buffers
with N CPU cores performs noticeably worse in the async case.
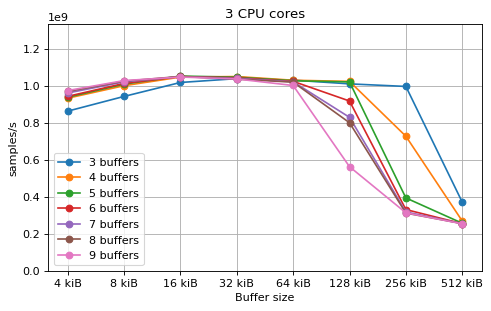
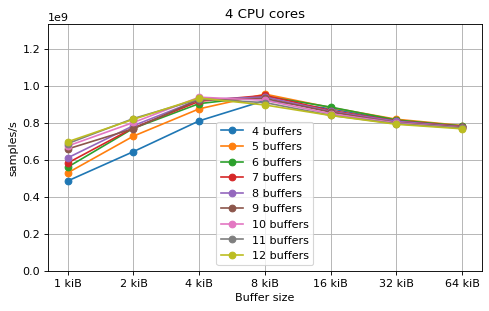
Multi-core async with fake message passing¶
This is a benchmark with async channels and without fake message passing. The results are very similar to the corresponding sync channels benchmark. This shows that the overhead of async channels is very small, despite them being much slower than the sync channels in the Rust channels benchmark.
A difference between async and sync channels is that using only N buffers
with N CPU cores performs noticeably worse in the async case.
Multi-kernel benchmarks¶
These benchmarks study the performance of running multiple Saxpy kernels,
distributed statically over several CPU cores. For N CPU cores and M >=
N kernels, if N divides M, each CPU core gets M/N kernels. If
N does not divide M, then the first M % N CPU cores get
floor(M/N) + 1 kernels and the remaining CPU cores get floor(M/N)
kernels.
Observe that with this strategy the maximum performance is 1.333 Gsps /
ceil(M/N), because there is always at least one CPU core that needs to run
ceil(M/N) kernels. When M does not divide N, this is worse than an
ideal scheduler that distributes all the M kernels dynamically over the
N available CPU cores, which has a performance of 1.333 Gsps * N / M.
For each CPU core, there is a thread pinned to the core. Each thread has a list of kernels that it owns. The threads are connected in a loop using channels as in the multi-core benchmarks. Likewise, a certain number of buffers are inserted in the receive channel of the first thread before the benchmark starts. Each thread receives a buffer from its input channel, iterates through its list of kernels, running each kernel on the buffer, and then sends the buffer to the next thread through the output channel.
As in the multi-core benchmarks, the sync and async case are tested. The sync
case uses qsdr::channel::futex channels, and the async case uses
qsdr::channel::futures channels with a block_on executor from
qsdr-benchmarks running independently on each thread.
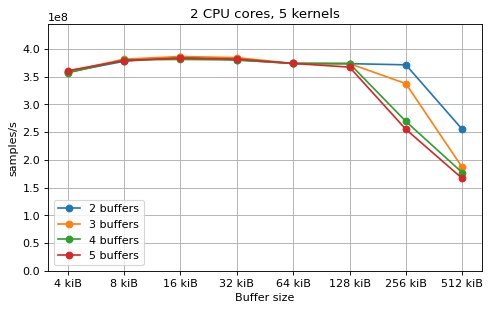
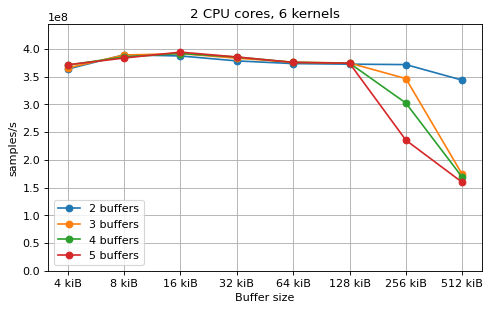
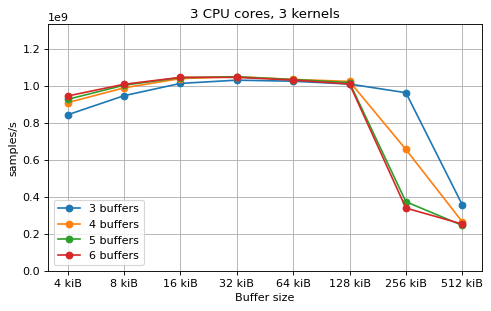
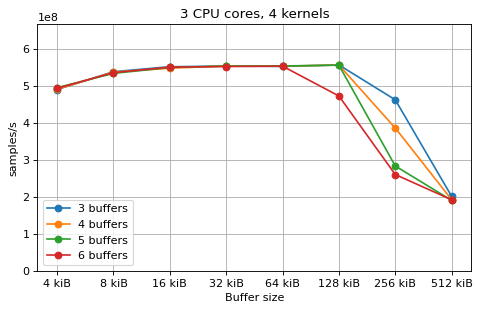
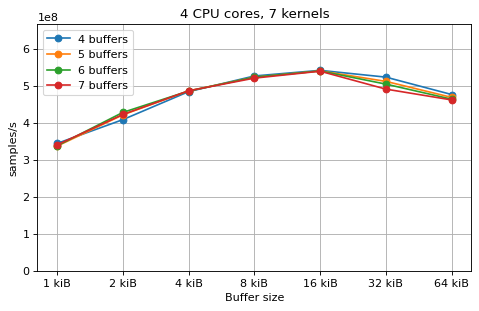
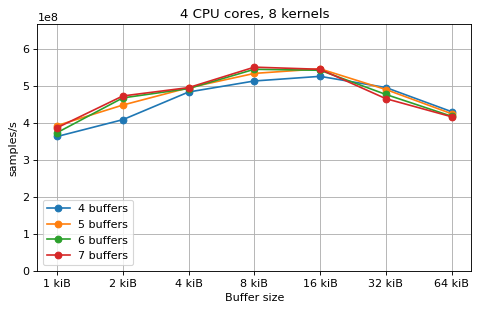
Multi-kernel¶
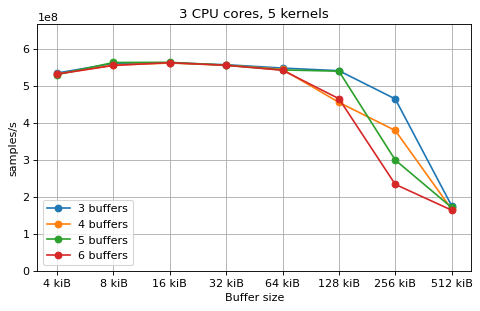
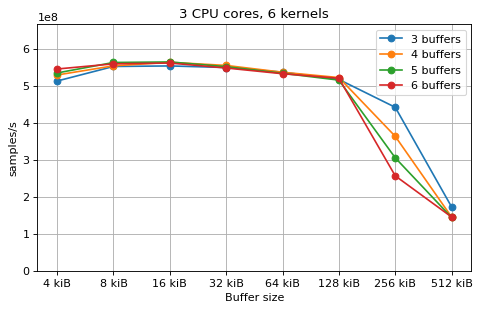
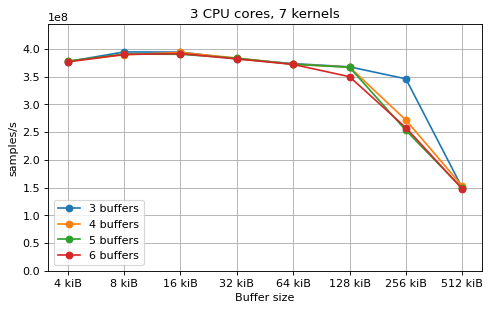
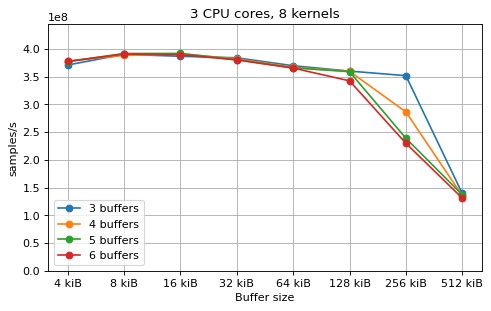
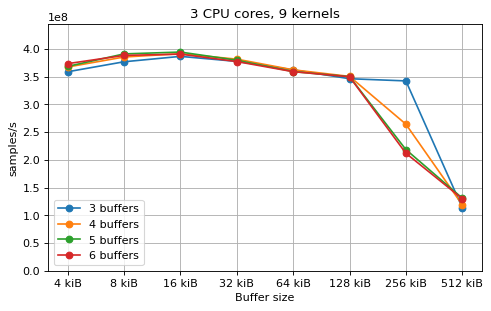
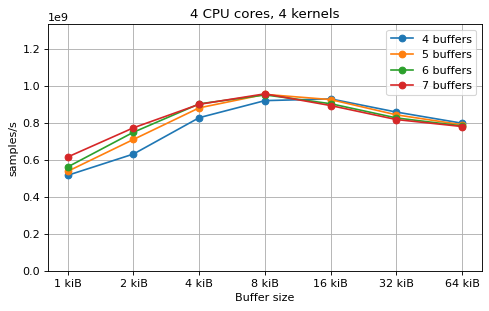
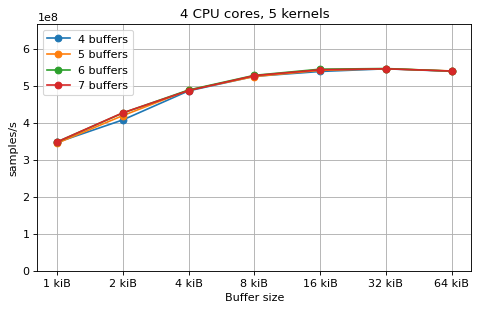
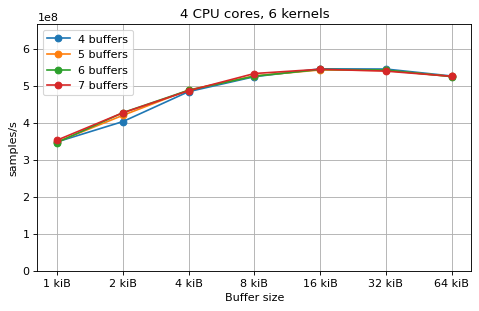
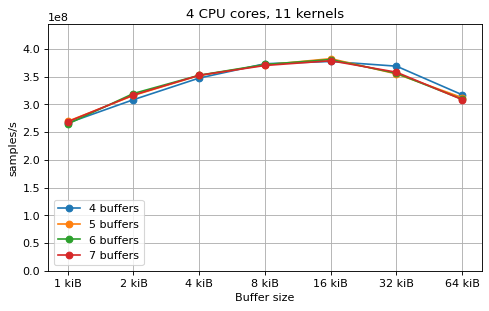
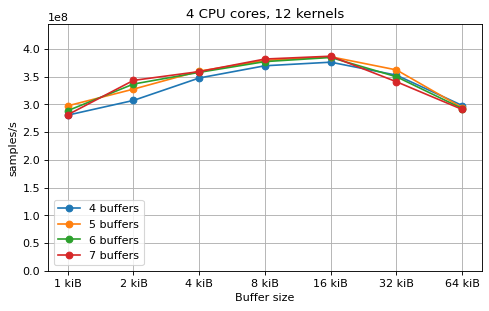
This is a benchmark with sync channels. The following figures show the
performance depending on the number of buffers and buffer size for different
choices of CPU cores and kernels. The theoretical maximum performance of 1.333
Gsps / ceil(M/N) is used as the maximum value of the y axis of the
plots. Similarly to the multi-core benchmarks, the number of buffers only makes
a small difference in performance as long as all the buffers fit in the L2
cache.
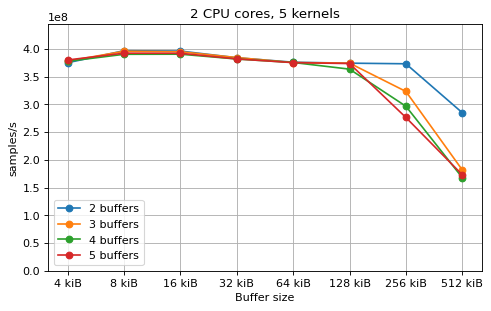
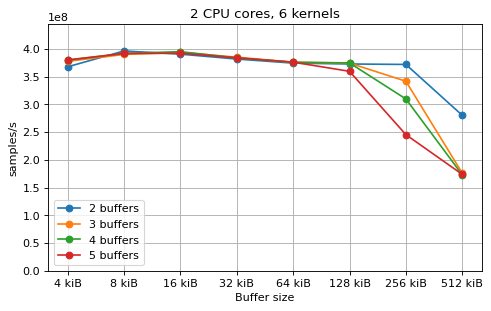
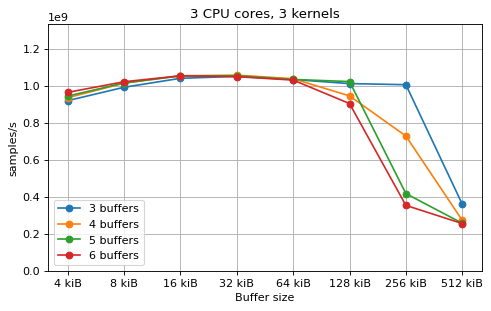
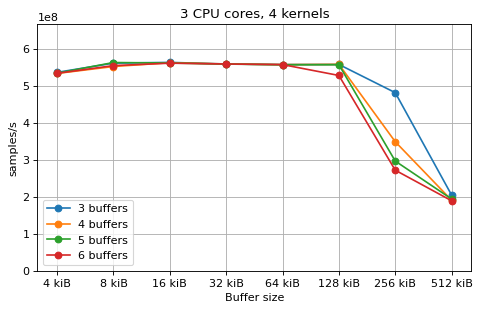
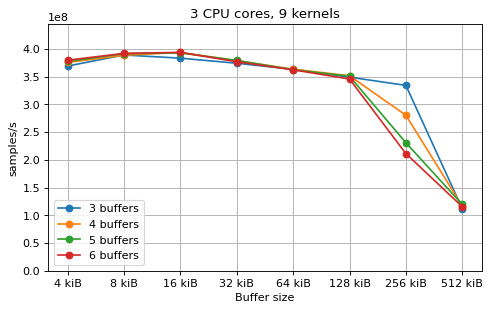
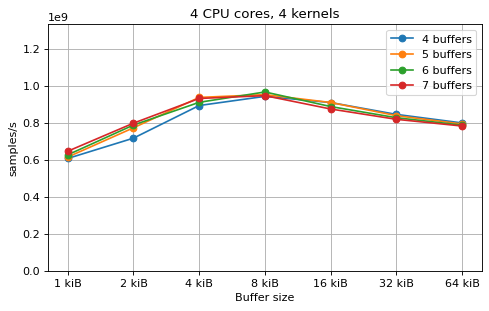
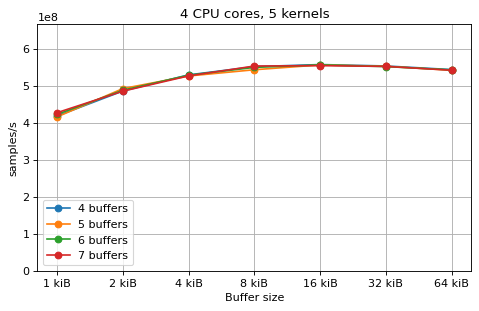
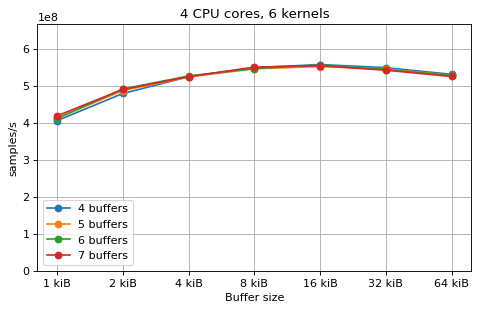
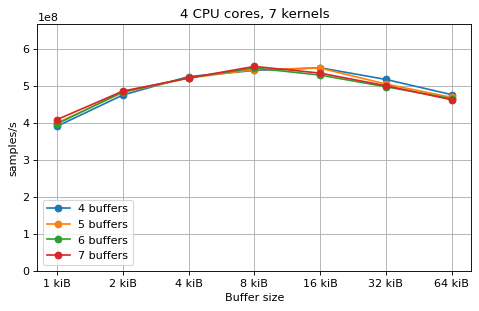
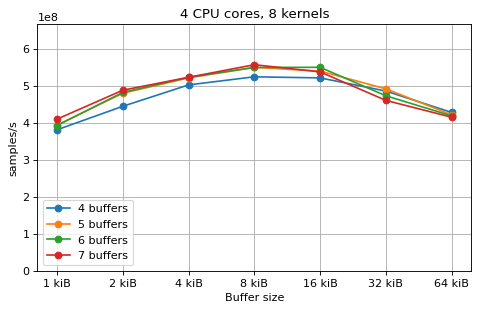
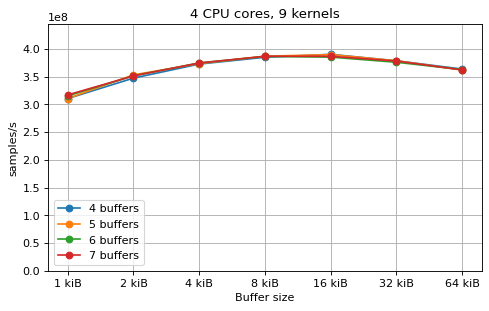
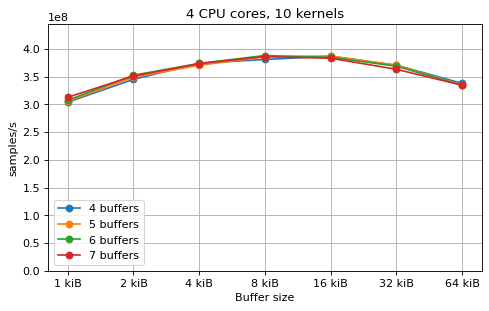
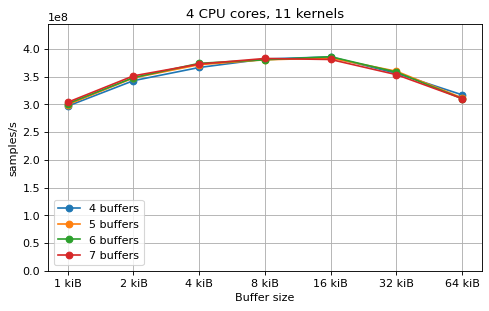
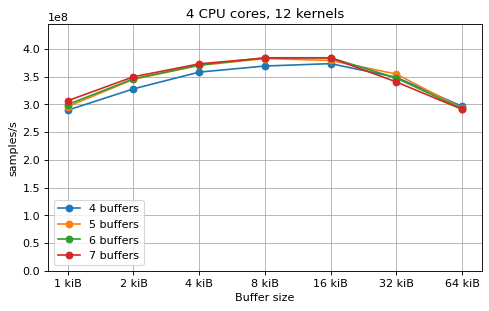
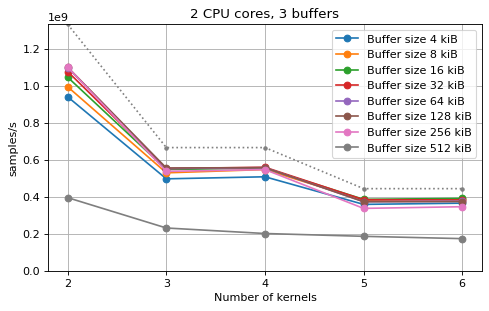
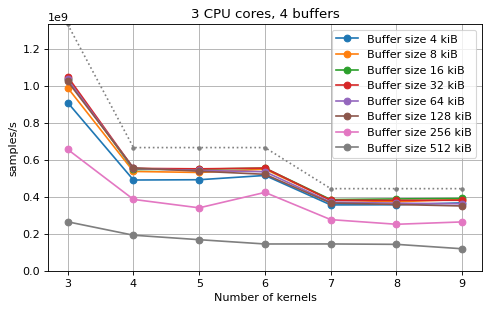
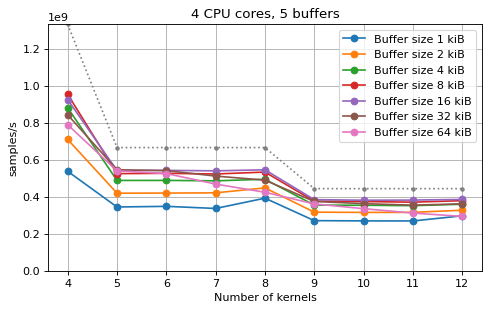
The following plots fix the choice of the number of buffers to N+1, where
N is the number of CPU cores. There is a plot for each value of N, where
the performance depending on the number of kernels and buffer size is
compared. The theoretical maximum performance of 1.333 Gsps / ceil(M/N) is
shown as dotted line for reference. These plots show that buffer sizes between 8
and and 32 kiB provide reasonable performance in all cases.
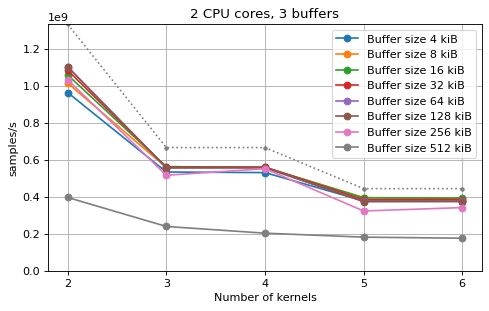
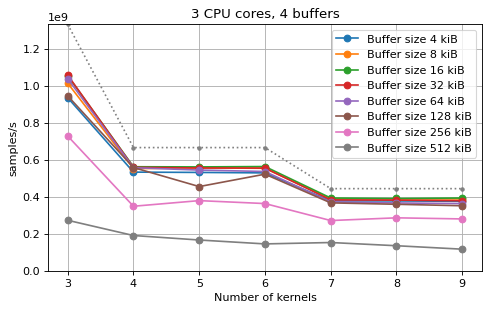
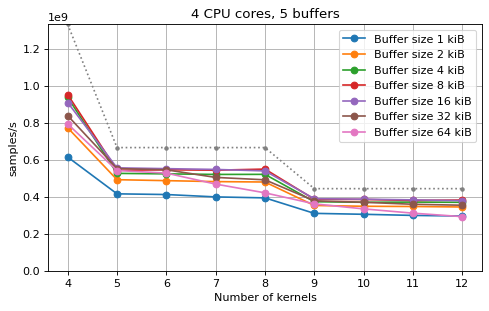
Multi-kernel async¶
This is a benchmark with async channels. The following figures show the
performance depending on the number of buffers and buffer size for different
choices of CPU cores and kernels. The theoretical maximum performance of 1.333
Gsps / ceil(M/N) is used as the maximum value of the y axis of the
plots. Similarly to the multi-core benchmarks, the number of buffers only makes
a small difference in performance as long as all the buffers fit in the L2
cache. The results are very similar to the ones using sync channels, except that
using M = N gives noticeably worse performance in some cases.
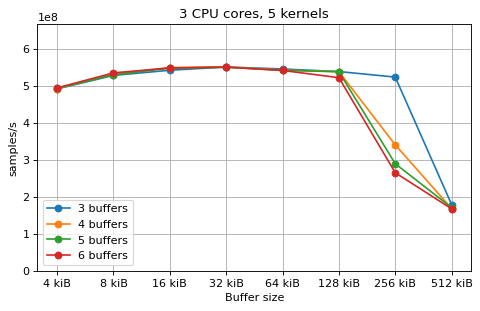
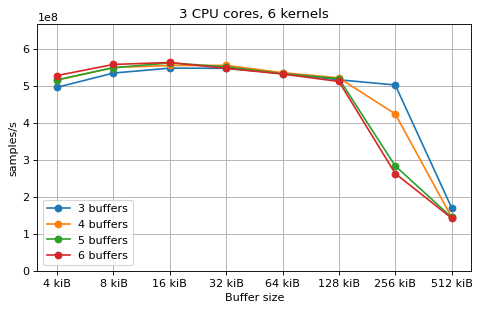
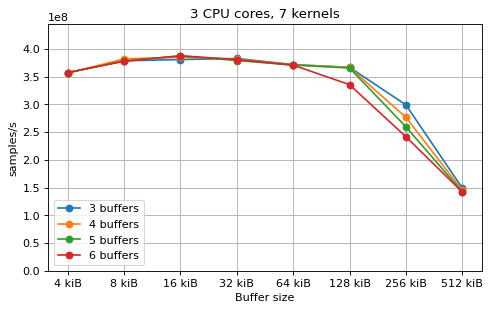
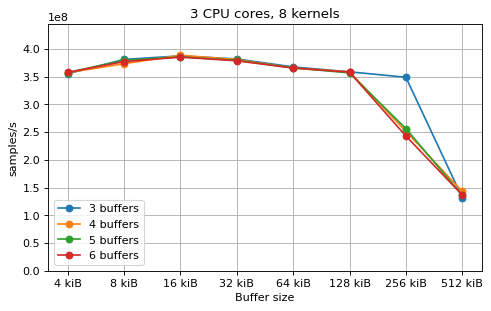
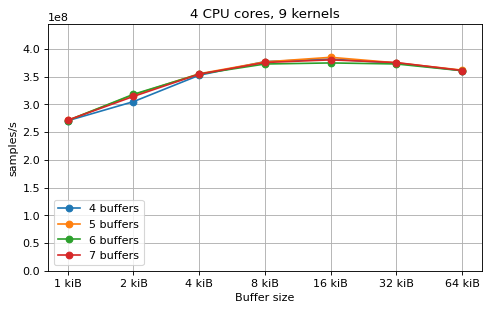
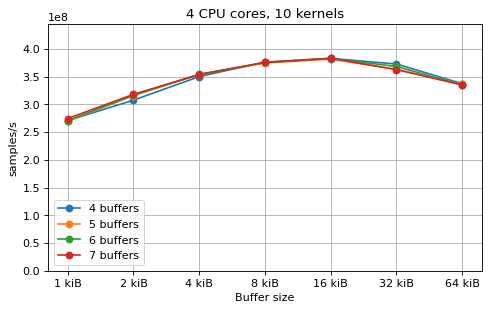
The following plots fix the choice of the number of buffers to N+1, where
N is the number of CPU cores. There is a plot for each value of N, where
the performance depending on the number of kernels and buffer size is
compared. The theoretical maximum performance of 1.333 Gsps / ceil(M/N) is
shown as dotted line for reference. These plots show that buffer sizes between 8
and and 16 kiB provide reasonable performance in all cases.